
Java
String
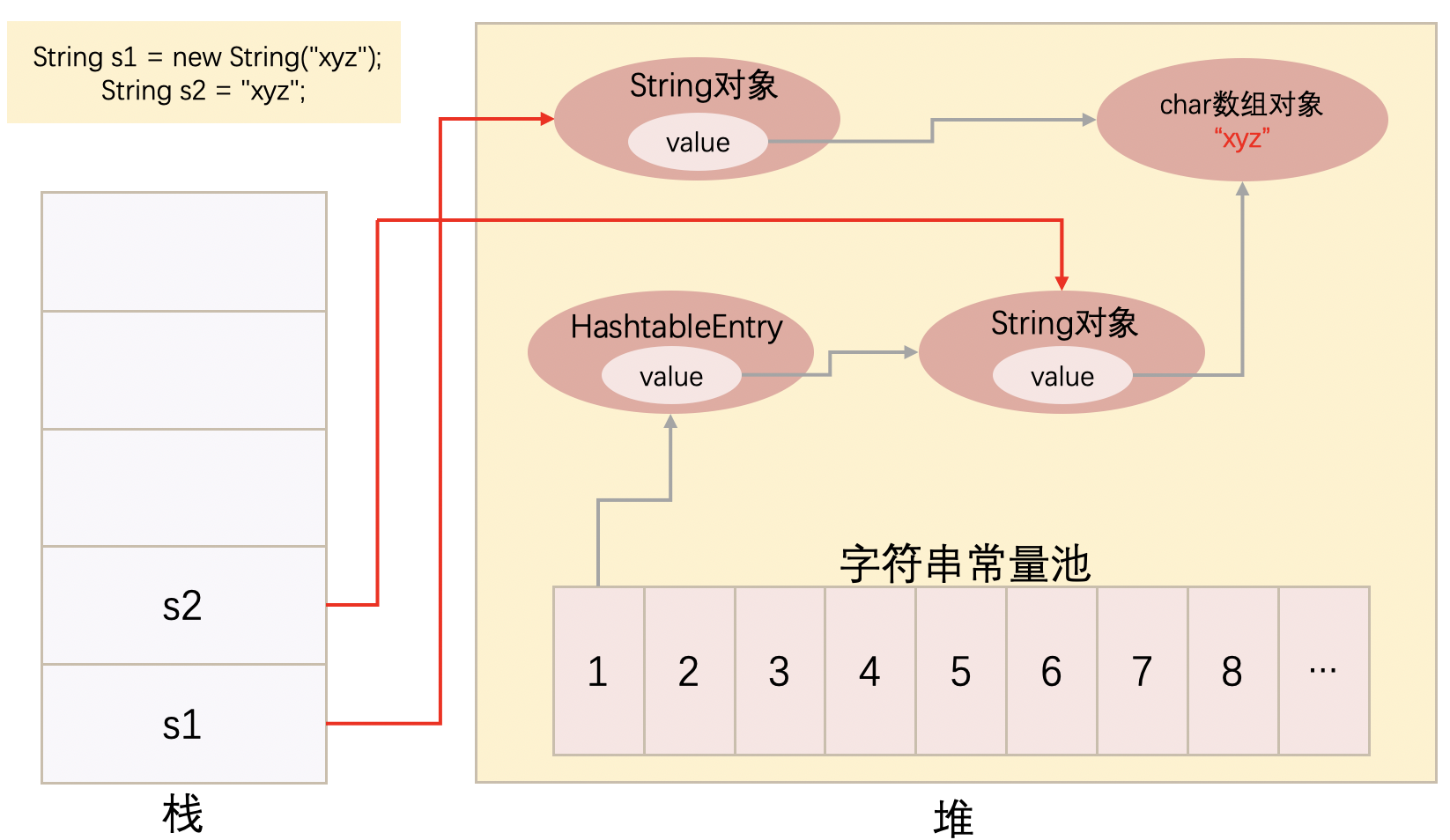
new 的形式创建
String a = new String("aabb");
当常量池中没有”aabb“的时候,就创建两个String对象和一个“aabb”对象,一个String对象被 a 引用,另一个被放入常量池当中。
当常量池中有“aabb”的时候,只创建一个String对象,这个String对象就是 a 的引用。String对象直接指向常量池已有“aabb”对象。
(反正就是要有两个String对象,是不是我建的没有关系··· 但是也有例外,比如直接 new String(“aabb”) 不定义变量的时候,就只创建一个String对象在常量池)
用 = 号创建
String b = "aabb";
当常量池中没有”aabb“的时候,就创建一个String对象和一个”aabb“对象。
当常量池中有”aabb“的时候,就不再创建对象,直接引用常量池中指向”aabb“的String对象。
字符串拼接
String s1 = "aa";
String s2 = "bb";
String str1 = s1 + s2;
String str2 = "aabb";
//为什么输出的是false
System.out.println(str1 == str2);
字符串拼接底层用的是StringBuilder来拼接,StringBuilder的toString()方法new出来的“aabb”对象不会被放到常量池中去。也就是说只会创建一个String对象和一个”aabb“对象,而且是一定会创建一个String对象和一个”aabb“对象。
如果我想让toString()方法产生的字符串驻留到常量池怎么办?用 intern() 方法,intern()方法可以把String()对象驻留到常量池中。
编译优化
final String s3 = "cc";
final String s4 = "dd";
String str3 = s3 + s4;
String str4 = "ccdd";
//为什么输出的是true呢???
System.out.println(str3 == str4);
用final修饰后,JDK的编译器会识别优化,会把String str3 = s3 + s4;优化成String str3 = "ccdd"。
所以上面的代码就相当于:
String str3 = "ccdd";
String str4 = "ccdd";
System.out.println(str3 == str4);
抽象类、接口
- 抽象类要被继承,接口要被实现。
- 接口只能做方法声明,抽象类还可以做方法实现。
- 接口可以多继承,抽象类(类)只能单继承。
- 抽象类可以没有抽象方法。但如果一个类有抽象方法,那它只能是抽象类。
- 抽象类的抽象方法必须要被子类全部实现,否则子类只能是抽象类。接口里面的方法也必须要被实现类全部实现,否则实现类也只能是抽象类。
动态代理和静态代理
静态代理:
- 目标对象是固定的。
- 目标对象要在程序执行之前创建完成。
- 不灵活,可能引发类爆炸(一个代理对象只能代理一个目标对象,造成要创建的代理对象过多)。
动态代理(JDK动态代理和cglib动态代理):
- 目标对象不是固定的
- 目标对象在代理时动态创建
共同点:
- 代理对象都可以增强目标对象的行为
注意事项:
JDK 动态代理的目标对象必须有接口实现,JDK 的动态代理依靠接口实现,如果有些类并没有接口实现,则不能使用 JDK 代理,只能用cglib代理,cglib 是针对类来实现代理的,它的原理是对指定的目标类生成一个子类,并覆盖其中方法实现增强,但因为采用的是继承,所以不能对 final 修饰的类进行代理。
JDK代理与CGLIB代理的区别
- JDK 动态代理是实现接口,Cglib 动态代理是继承
- JDK 动态代理(目标对象存在接口时)执行效率高于 Ciglib,如果目标对象有接口实现,选择 JDK 代理,如果没有接口实现选择 Cglib 代理
过滤器、拦截器、监听器
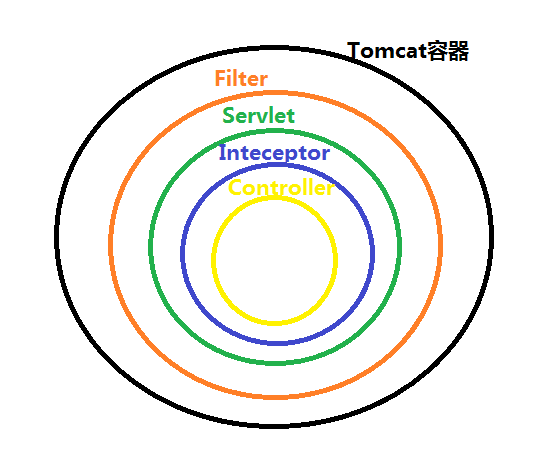
过滤器与拦截器有相似之处,比如都能实现权限检查,日志记录等等,不同的是:
- 范围不同:过滤器是servlet规范中定义的,是servlet容器支持的,所以只能用于web程序,而拦截器是spring内的,是spring框架支持的,所以它不仅仅局限于web程序。
- 可使用资源不同:拦截器可以使用spring的任何资源和对象,比如bean、事务管理、数据源等。过滤器则不可以。
- 深度不同:过滤器只能用于servlet前后,而拦截器能用于方法前后,异常抛出前后等等。
启动顺序
监听器 ---> 过滤器 ---> 拦截器
锁
synchronized
synchronized是Java内置的同步机制,它具有互斥性和可见性,当一个线程已经获得锁的时候,其它线程便只能等待或者阻塞。
在jdk6的时候,synchronized得到了很大的改进,它可以分为三种状态的锁,偏向锁、轻量级锁和重量级锁。偏向锁可以通过锁膨胀的方式进化成重量级锁。
锁膨胀
偏向锁是为了在没有多线程的情况下,尽量减少锁带来的性能开销。
当线程数量变多的时候,偏向锁就会升级为轻量级锁,其它线程会通过自旋的形式尝试获得锁,不会阻塞,提高性能。
当线程自旋到一定次数得时候,还没有获得锁,就会进入阻塞,轻量级锁就会膨胀为重量级锁,重量级锁会让其它线程进入阻塞,影响性能。
局限性
- 不可以响应中断。其它线程获得锁的时候,当前线程只能等待或阻塞。
- 读-读操作也需要排队,影响性能。
Reentrant Lock
reentrant lock是可重入锁,synchronized也是可重入锁,那 reentrant lock 有什么特点呢?
第一点:reentrant lock 可以尝试非阻塞地获取锁。如果没有获取获取到锁就直接返回。
第二点:reentrant lock 可以超时获得锁,就是等待了指定得时间仍然没有获得锁就直接返回。
第三点:reentrant lock 可以响应中断,不用一直等待。
第四点:reentrant lock 可以自由设置成公平锁和非公平锁,而synchronized只能是非公平锁。
第五点:synchronized不需要手动开启和释放锁,reentrant lock 需要。
第六点:synchronized可以修饰方法和代码块,reentrant lock 只能修饰代码块。
read-write lock
读写锁就很容易理解了,除了读-读不冲突,读写,写读,写写都是冲突的,都需要等待。
多线程
线程的状态有哪几个?
- 新建 New
- 就绪 Runnable (就是可执行的状态)
- 运行 Running
- 阻塞 Blocked
- 死亡 Dead
线程要怎么创建
- 继承Thread线程类
- 实现Runnable接口
volatile
volatile 是一个变量修饰符,用来修饰会被不同线程访问和修改的变量。
它有三个特性
- 保证线程间的可见性
- 不保证原子性
- 禁止指令重排序
怎么保证可见性
被 volatile 修饰的变量,在被某个线程修改之后会立即刷新到主内存当中,其它线程通过不断的嗅探得知自己工作内存当中该变量的副本已经失效,就会从主内存当中重新读取最新的值。所以这就可以保证每次读到的值都是最新的,做到了线程间的可见性。
如何做到禁止指令重排序
Java编译器在生成指令时,在适当的位置插入了内存屏障指令来禁止重排序。
volatile的代价
使用volatile也是有代价的,前面说怎么保证可见性的时候也说了,线程需要通过不断的嗅探主内存的数据来判断它的值是否已经失效了,那么无效的交互就会有很多,如果使用volatile修饰的变量有很多,不断的交互就有可能让总线宽带达到峰值,造成总线风暴。所以什么时候使用volatile,什么时候使用锁,需要根据场景来区分,不要一味使用volatile。
threadlocal
被threadlocal修饰的变量都会被set到每一个线程的本地变量Map当中,此后线程操作的都是本地的这个副本,也就没有了线程安全问题。
线程池
线程池有哪些状态
Running:正常运行状态。
shutdown:不再接收新任务。
stop:不再接收新任务,并抛弃队列里面的任务,中断正在执行的任务。
tidying:所有任务已执行完毕,shutdown 和 stop 都尝试更新为这个状态。
terminated:终止状态。
线程池的处理流程(重点)
当提交一个新任务的时候,首先判断核心线程池是否有空闲线程,如果有,就用空闲线程执行。
如果没有,就判断任务队列是否已满,如果没满,就放到任务队列当中。
如果任务队列满了,就判断线程池是否已满(已达到最大线程数,不是核心线程数),如果没满,就创建一个新的线程执行。
如果线程池也满了,那就执行饱和策略。
核心线程池---》队列 ---》线程池 ---》执行饱和策略
线程池饱和策略有哪些
ThreadPoolExecutor.AbortPolicy:丢弃任务并抛出RejectedExecutionException异常。
ThreadPoolExecutor.DiscardPolicy:也是丢弃任务,但是不抛出异常。
ThreadPoolExecutor.DiscardOldestPolicy:丢弃队列最前面的任务,然后重新尝试执行任务(重复此过程)
ThreadPoolExecutor.CallerRunsPolicy:由调用线程处理该任务
IO
BIO (Blocking I/O):同步阻塞I/O模式。
NIO (New I/O):同步非阻塞I/O模式。
AIO (Asynchronous I/O):异步非阻塞I/O模型。
反射
反射的三种方式:
- 对象名.getClass
- 类名.class
- Class.forName()
Object
object有哪些方法:(不全)
- getClass()
- hashCode()
- equals()
- toString()
- clone()
- wait()
- notify()
当线程获得锁的时候,也就是在同步代码块或同步方法里头才能调用 wait() 和 notify() 方法。因为调用 wait() 方法会释放锁,你要释放锁必须得先有锁吧。
wait() 和 sleep() 的区别:wait会释放锁,而sleep不会释放锁。
容器
ArrayList
ArrayList的特点如下:
- 有序列表
- 允许元素重复,允许存储null值
- 动态扩容
- 非线程安全
ArrayList底层使用的是数组,每次扩容都是原来的**1.5**倍,容量最大值是 Integer.MAX_VALUE - 8
HashMap
hashmap的本质就是一个元素是链表和红黑树的数组。
hashmap在扩容时,把数组的长度扩大一倍,然后把原本的数据一一读取出来,重新hash分配到新的桶当中。
//默认初始化容量初始化=16
static final int DEFAULT_INITIAL_CAPACITY = 1 << 4; // aka 16
//最大容量 = 1 << 30
static final int MAXIMUM_CAPACITY = 1 << 30;
//默认加载因子.一般HashMap的扩容的临界点是当前元素数量 > HashMap的大小 * 加载因子
//DEFAULT_LOAD_FACTOR * DEFAULT_INITIAL_CAPACITY = 0.75F * 16
static final float DEFAULT_LOAD_FACTOR = 0.75f;
//当hash桶中的某个bucket上的结点数大于该值的时候,会由链表转换为红黑树
static final int TREEIFY_THRESHOLD = 8;
//当hash桶中的某个bucket上的结点数小于该值的时候,红黑树转变为链表
static final int UNTREEIFY_THRESHOLD = 6;
//桶中结构转化为红黑树对应的table的最小大小
static final int MIN_TREEIFY_CAPACITY = 64;